여태 까지 이론적으로 알고 있던 인덱스의 종류 (단일, 복합, 커버링) 인덱스에 대하여 직접 설정을 해보고 그 효과에 대하여 실습을 해보려고 합니다.
Table 구조

구조를 조금 단순화 하기 위하여 Member Table에서 PK에 해당하는 member_id와 회원이 거주하는 도시 city 그리고 상세 거주 지역 관련 정보 location, 마지막으로 회원의 이름 name등 4가지 칼럼을 생성하고 이에 대해 각각 인덱스를 거는 방식을 달리 함에 따라 실습을 진행할 에정입니다.
데이터 생성
CREATE DEFINER=`performance`@`%` PROCEDURE `insertMembers`()
BEGIN
DECLARE i INT DEFAULT 1;
DECLARE j INT DEFAULT 1;
DECLARE K INT DEFAULT 1;
DECLARE c VARCHAR(200);
DECLARE l VARCHAR(200);
START TRANSACTION;
WHILE i <= 2500 DO
SET c = UUID();
WHILE j <= 400 DO
SET l = UUID();
WHILE k <= 10 DO
INSERT INTO member (city, name, location) VALUES (c, UUID(), l);
SET k = k+1;
END WHILE;
SET k = 1;
SET j = j+1;
END WHILE;
SET j = 1;
SET i = i+1;
END WHILE;
COMMIT;
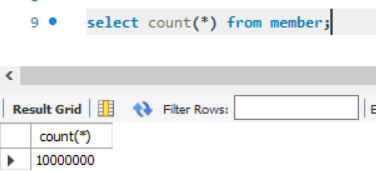
END다음과 같이 MySQL Procedure 함수를 통하여 10,000,000건의 더미데이터를 생성하였습니다. 총 2500 종류의 도시와 1,000,000 종류의 상세 지역 정보가, 10,000,000 종류의 이름이 있는 회원 데이터를 반복문을 사용하여 생성하였습니다.

조회 쿼리 성능 분석 (단일 인덱스)


1000만 건이 넘는 데이터에서 특정 도시에 거주하는 member 데이터들을 찾으려면 다음과 같이 10초가 넘는 시간이 소요됩니다.
하지만 아래와 같이 인덱스를 설정해주면 훨씬 쿼리 속도가 빨라진 것을 알 수 있습니다. 10초가 넘게 걸리던 쿼리 속도가 0.015초로 단축되었습니다.


조회 쿼리 성능 분석 (복합 인덱스)
단일 인덱스만 있으면 충분한 성능 향상이 가능한데 왜 복합 인덱스가 필요한 것일까요? 만약 특정 도시에서 특정 지역에 사는 회원을 조회한다고 가정해봅시다.


보면 쿼리 성능이 꽤 준수한 것을 알 수 있습니다. where 조건에서 city 칼럼이 인덱스가 걸려있기 때문에 location 탐색 범위가 4000개 밖에 안되기 때문에 테이블 풀 스캔을 하더라도 굉장히 짧은 시간이 걸리게 되는 것입니다.
만약 서비스가 활성화 되어서 특정 도시에 사는 지역 정보가 급격하게 증가하게 된다면 어떻게 될까요?
CREATE DEFINER=`performance`@`%` PROCEDURE `insertLocation`()
BEGIN
DECLARE i INT DEFAULT 1;
START TRANSACTION;
WHILE i <= 1000000 DO
INSERT INTO member (city, location, name) VALUES ('53e93efa-ff83-11ed-8bb1-005056c00001', UUID(), UUID());
SET i = i+1;
END WHILE;
COMMIT;
END다음과 같이 Procedure을 통하여 특정 도시에 지역명을 랜덤 UUID로 하여 100만 건 정도의 데이터를 생성해줍니다. 그럼 특정 도시는 이전에 생성한 4,000 건의 데이터와 100만 건 정도의 데이터를 합하여 1,004,000 건의 데이터를 갖게 됩니다.


이 상황에서 해당 도시의 특정 지역을 조회하게 되면 성능이 어떻게 나올까요?


4000 건의 도시 정보를 인덱스를 활용하여 특정 도시를 빨리 찾는다 하여도, 특정 도시에 연관된 지역 정보가 100만 건이 넘기 때문에 이를 Table Full Scan을 하게 되면 5초가 넘는 시간이 걸리게 됩니다.
이럴 경우 기존 단일 인덱스를 복합 인덱스로 바꾸게 되면 어떻게 될까요?

다음과 같이 기존의 city 인덱스를 지워주고 city와 location을 합친 city_location 복합 인덱스를 만들어 줍니다.
이 떄 중요한 점은 괄호안에 있는 칼럼의 순서입니다. 위와 같이 설정해주게 되면 where 절에 city와 location이 있을 경우 city에 대한 정보를 먼저 필터링 하여 찾고, 필터링 된 데이터에서 location을 찾는 순서로 실행되게 됩니다.

복합 인덱스를 설정해주고 난 뒤에 특정 도시에 속하는 특정 지역을 검색하는 쿼리의 성능이 향상된 것을 볼 수 있습니다.
5초가 넘게 걸렸던 쿼리가 0.016초로 단축되었습니다.
그럼 city에 대한 인덱스가 삭제된 상태니까 특정 city를 찾는 성능은 감소했을까요?


특정 도시를 찾는 쿼리 성능은 그대로인 것을 확인할 수 있습니다. 조금만 생각해보면, 복합 인덱스 순서 상 city가 앞에 있으니까 city순서로 먼저 정렬 한 후에 각각의 city에서 location 별로 정렬을 수행하게 됩니다. 따라서 특정 city를 찾을 때는 단일 인덱스 없이도 빠르게 찾을 수 있는 것이죠.
하지만 특정 location을 찾을 때는 성능이 어떻게 될까요?


예상하셨겠지만, city 정렬이 먼저 된 후에 location이 정렬되기 때문에 사실상 특정 location을 찾을 경우에는 인덱스 효과를 보기 힘듭니다.
따라서 db 옵티마이저는 인덱스를 쓰지 않고 테이블 풀스캔을하게 됩니다. 따라서 시간이 10초가 넘는 슬로우 쿼리가 발생하게 되는 것이죠.

위와 같이 explian 키워드를 써서 쿼리 수행이 어떻게 되었는지 한번 확인해봅시다.

보시면 key가 비어있는것을 볼 수 있습니다. 이는 옵티마이저가 인덱스가 있음에도 테이블 풀스캔을 하는게 더 유리하다는 판단을 하여 인덱스를 타지 않고 쿼리를 수행한 것입니다.
반면에 특정 city를 찾을 때는 다음과 같이 key값에 어떤 index를 사용했는지 여부가 나타납니다.
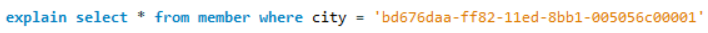

정리하자면, 복합 인덱스는 여러 조건이 있을 경우 특정 조건에 해당하는 칼럼은 인덱스로 필터링이 빠르게 되더라도, 다른 조건에 있는 칼럼은 인덱스가 되어 있지 않아서 많은 소요시간이 걸릴 때, 두 칼럼을 합쳐서 인덱스를 거는 방식입니다. 또한 인덱스를 설정할 때 칼럼의 순서가 매우 중요한 것을 위와 같은 예시를 통해서 알 수 있습니다
조회 쿼리 성능 분석 (커버링 인덱스)
커버링 인덱스란 무엇일까요? 쉽게 말하면 쿼리를 충족하는데 필요한 모든 데이터를 갖고 있는 인덱스를 말합니다.
city와 location을 city_location_index라는 복합인덱스로 설정한다면,

다음과 같이 city와 location의 칼럼만 select하는 쿼리가 있을 때 city_location_index는 커버링 인덱스가 되는 것입니다.
원래 인덱스는 특정 데이터를 찾을 때 인덱스 테이블을 한번 거친 다음에, 테이블에 있는 포인터를 통해 데이터가 물리적으로 저장된 위치를 쉽게 갈 수 있는 원리로 작동합니다.
근데 커버링 인덱스는 쿼리문 에서 요구하는 모든 데이터가 이미 인덱스에 있기 때문에 실제 물리적으로 저장된 위치에 갈 필요 없이 한번에 바로 반환이 가능하게 됩니다.


위의 쿼리는 member의 전체 데이터를 가져오는 쿼리문입니다. 복합인덱스를 사용했기 때문에 쿼리 수행속도가 매우 빠른 곳을 볼 수 있습니다.


위 쿼리는 member 데이터 중 index에 속하는 city와 location만 가져오는 쿼리문입니다. 수행속도가 미세하게 더 빠르긴 하지만 큰 차이를 보이진 않습니다.
Explain 키워드를 써서 쿼리 실행이 어떻게 되었는지 살펴보면

전체 데이터를 가져오는 경우 똑같은 인덱스를 썻지만 오르쪽 맨 끝에 Extra 부분이 비어있는것을 볼수 있습니다.
반면에 아래와 같이 인덱스에 속하는 특정 인덱스를 가져오는 경우 Extra 부분에 using Index 표시가 있는것을 볼 수 있습니다. 즉 index만을 사용하여 데이터를 가져오는 커버링 인덱스가 적용된 것을 이를 통해 확인할 수 있습니다.

이상으로 인덱스에 관련된 실습 정리를 마치겠습니다.
글 읽어주셔서 감사합니다.
'DB' 카테고리의 다른 글
| JPA 관련 주의 사항 정리 (0) | 2023.08.28 |
|---|---|
| 마이페이지 쿼리 성능 점검 (1) | 2023.08.28 |
| 옵티마이저란? (0) | 2023.05.19 |
| DB 쿼리 성능을 개선해보자 (0) | 2023.04.05 |
| 식별관계와 비식별관계 (0) | 2023.03.28 |