B-Tree
B-트리란 트리 자료구조 중에 하나입니다. 여기서 B는 Balanced(균형)을 뜻합니다. 이 말의 즉슨, 트리의 형태가
균형을 이룬다는 것을 뜻합니다. 트리 자료구조의 효율성에 있어서 균형은 매우 중요합니다.

다음 그림을 보면 왼쪽은 트리가 균형적이지 않아 오른쪽 트리보다 탐색에 필요한 횟수가 더 많이 소요되는 것을 알 수 있습니다.
B 트리의 경우 삽입과 삭제시 필요하면 스스로 균형을 유지합니다. 또한 하나의 노드에 여러 자료가 배치됩니다.만약 한 노드에 M개의 자료가 배치되면 이를 M차 B-Tree라고 부르게 됩니다. 여기서 중요한 점은 모든 노드가M개로 꽉차 있어야 되는 것을 의미하는건 아닙니다. 한노드에 포함된 최대 자료 갯수를 기준으로 산정합니다.

위와 같은 경우 한 노드에 D, E, F, G 최대 4개의 데이터가 담겨있으므로 이는 4차 B-Tree라고 할 수 있습니다.
또는 한 노드에 담기는 M의 갯수가 홀수인지 짝수인지에 따라 알고리즘이 달라지는 특성이 있습니다.
B-Tree 특징
다음으로 B-Tree의 특징에 대해 살펴보도록 하겠습니다.
1. 노드의 자료수가 N이면, 자식의 수는 N+1이어야 합니다.
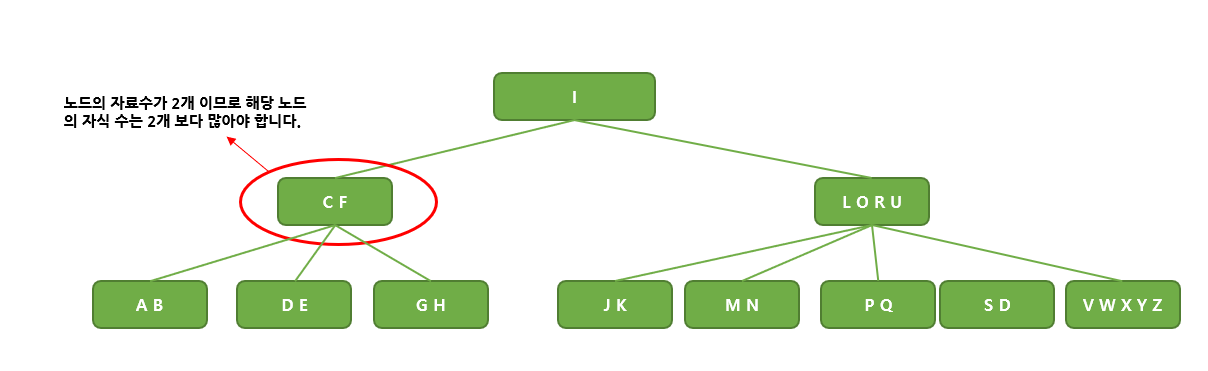
위와 같이 C F라는 자료를 가진 노드는 해당 자료 수인 2개 보다 3개의 노드를 자식으로 지니고 있는 것을 알 수 있습니다.
2. 각 노드의 자료는 정렬 된 상태여야 합니다.
위의 그림 3의 각 노드들은 알파벳이 오름차순으로 정렬된 상태인 것을 확인 할 수 있습니다.
3. 노드의 자료 D(k) 의 왼쪽 서브트리는 D(k)보다 작은 값들이고 D(k)의 오른쪽 서브트리는 D(k)보다 큰 값들이어야 합니다.
이 말을 위의 그림을 예로 설명하자면, C F를 가지고 있는 노드의 왼쪽 자식 노드의 자료값들은 C F 보다 작은 A B로
이루어져 있습니다. 반면 오른쪽 자식 노드는 C F 보다 큰 G H로 이루어져있습니다. 중간에 있는 자식 노드는 C와 F의
사이 값인 D E로 이루어져 있는 것을 알 수 있습니다.
4. Root노드는 적어도 2개 이상의 자식을 가져야 합니다.
이것은 1번 규칙을 통해서도 확인 할 수 있습니다. 루트 노드의 자료수가 1개면 최소한 자식 노드는 1+1인 2개의 노드를
가져야 하기 때문에 루트 노드가 존재한다면 적어도 2개 이상의 자식을 지녀야합니다.
5. Root 노드를 제외한 모든 노드는 적어도 M/2 개의 자료를 가지고 있어야 합니다.
그림 3의 경우를 예로 들어 보자면, 오른쪽 맨 끝에 노드가 자료 V W X Y Z를 지니고 있는 5차 B-Tree이므로모든 노드는 5 / 2 = 2개의 자료를 최소한 지니고 있어야 합니다. 따라서 위 B-Tree의 모든 노드는 최소 2개의 자료를 지니고 있는 것을 확인할 수 있습니다.
6. 외부 노드로 가는 경로의 길이는 모두 같아야 합니다.
여기서 말하는 외부노드는 자식 노드가 없는 Leaf Node를 뜻합니다. 그림 3의 경우 총 8개의 Leaf Node가 있는데
모두 depth 3의 레벨에 위치하고 있는 것을 알 수 있습니다.
7. 입력 자료는 중복 될 수 가 없습니다.
말의 뜻이 햇갈릴 수 도 있는데, 하나의 노드에 입력된 자료가 중복될순 없다는 것을 뜻합니다. 예를 들어하나의 노드에 A A A 의 자료가 있으면 자식 노드는 A와 A의 사이의 자료들을 지녀야 하는데, 그런 값은 존재하지않습니다. 따라서 한 노드에 입력 자료는 중복되어선 안됩니다.
B-Tree 활용
B-Tree는 db 인덱스 또는 파일 입출력에 많이 쓰여집니다.
DB 인덱싱 작업을 할 때 다양한 자료구조가 있음에도 불구하고 B-Tree를 쓰는 이유는 무엇일까요?
B-Tree는 최악의 경우에도 O(logN)을 보장합니다. 하지만 이것 보다 더 시간복잡도가 낮은
HashTable과 같은 자료구조도 존재합니다. HashTable은 시간복잡도가 O(1)에 해당합니다.
그럼에도 불구하고 HashTable을 db인덱스에서 자주 사용하지 않는 이유는 다음과 같습니다.
1. 첫번쨰 이유, Hash Collision (해시 충돌)
해시 충돌은 서로 다른 key가 하나의 출력 값을 나타내는 경우를 뜻합니다.
2. 두번째 이유, 순서
해시 테이블은 키 값들의 순서를 보장하지 않습니다. 하지만 쿼리를 작성하다보면 범위를
나타내는 부등호가 많이 쓰이죠.
SELECT * FROM user WHERE user.age >= 20;만약 위와 같은 쿼리를 HashTable을 활용하여 실행할 경우, age==20, age==21, age==22... 와 같이
해당하는 값을 찾아야 될 겁니다. 다시 말해 단 하나의 자료를 찾는데 있어서 O(1)의 시간복잡도를 보장해주긴 하지만
부등호가 쓰인 쿼리에서는 이러한 효율을 보장하지 못하게 됩니다.
3. 세번째 이유, 크기 조절
해시 테이블은 저장되는 요소ㅇ의 수가 늘어나거나 줄어들면 반드시 크기를 재조절 해야 합니다.
이 떄 성능 문제나 db 인덱스에 쓰이는 키 값이 지속적으로 변경되는 문제가 발생할 수 있습니다.
위와 같은 이유 때문에 보통 db 인덱스에서는 HashTable 대신에 B-Tree 자료구조를 활용하는 편입니다.
이상으로 B-Tree 자료구조에 대해서 살펴봤습니다. 긴글 읽어주셔서 감사합니다.
잘못된 부분이나 부족한 부분이 있을 시 댓글로 달아주시면 감사하겠습니다!
'CS > 자료구조' 카테고리의 다른 글
| 레드 블랙 트리(Red-Black Tree) (0) | 2023.04.21 |
|---|---|
| 이진 탐색 트리(BST)에 대하여 (0) | 2023.03.29 |
| Array와 List의 차이는? (0) | 2023.03.24 |
| Heap(힙)에 대하여 (0) | 2023.03.05 |
| HashTable이란? (0) | 2023.02.13 |